Machine learning platforms are all about performance, consistency, and scale. At the heart of these systems lies one critical component — the feature store.
For teams exploring feature store best practices, success depends on three things:
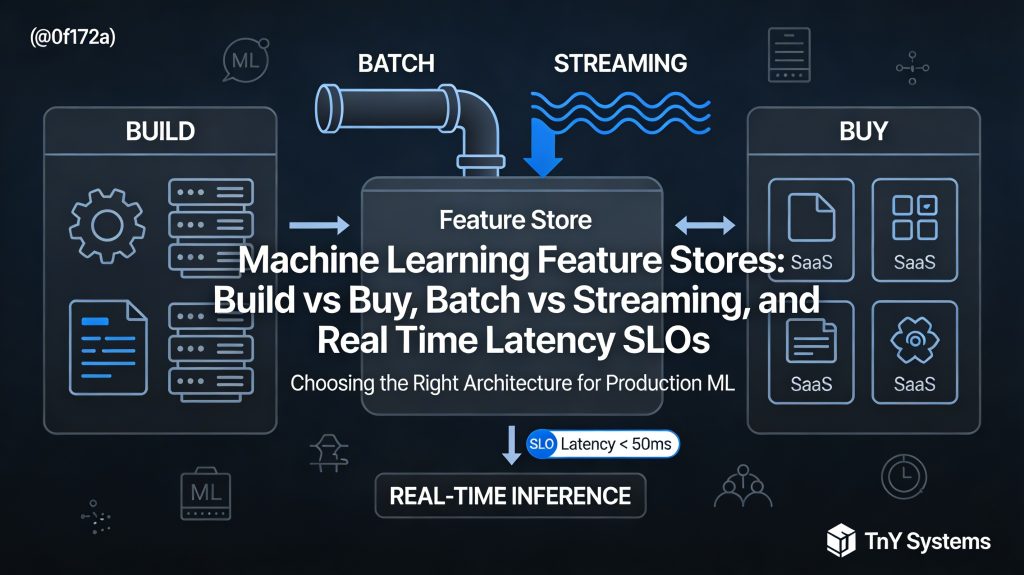
- Picking the right architecture (build vs buy)
- Balancing batch and streaming features
- Meeting strict real‑time latency SLOs
If your ML platform team is preparing for rollout or migration, this guide breaks down what matters most for scalable AI operations.
🧩 The Role and Value of Feature Stores
A feature store acts as the bridge between data and models. It ensures that training data matches production behavior — solving the notorious online/offline consistency challenge.
Key benefits include:
✅ Centralizing and standardizing features
✅ Reusing data assets across models
✅ Simplifying governance, lineage, and access
In distributed data ecosystems, the feature store is the glue connecting data lakes, warehouses, and streams — the layer that makes operational ML possible.
⚙️ Build vs Buy: Platform Strategy Decisions
🏗️ Build in-house
- Offers full flexibility and integration with internal systems.
- Allows optimization for security, cost, and infrastructure.
- Requires heavy engineering investment and continuous maintenance for scaling real‑time pipelines.
🛒 Buy or adopt managed solutions
- Fast deployment and out‑of‑the‑box reliability.
- Strong SDKs and data observability.
- Limited customization and potential vendor lock-in.
💬 Pro tip: Many teams start with a managed service, then evolve to hybrid models — combining vendor reliability with in‑house feature engineering pipelines.
🔄 Batch vs Streaming Features
Understanding how to mix batch features and streaming features is vital for cost and performance balance.
📦 Batch Features
- Generated on fixed schedules (daily/hourly).
- Ideal for use cases like recommendations or churn models.
- Lower cost and simpler to debug.
⚡ Streaming Features
- Continuously updated from event streams.
- Critical for real-time personalization, fraud detection, and IoT analytics.
- Require infrastructure built for low-latency ingestion and tight SLAs.
🧠 Architecture tip: Combine both — batch features for history and context, streaming features for immediacy and responsiveness.
⏱️ Meeting Real‑Time Latency SLOs
Real‑time prediction pipelines depend on strict latency budgets, often targeting under 100 ms end‑to‑end.
To meet those SLOs:
- Precompute and serve features from ultra-fast stores (Redis, DynamoDB, Cassandra).
- Use caching and asynchronous pre‑loading to avoid cold starts.
- Automate online/offline sync to maintain consistent model outputs.
🎯 Goal: Serve fresh, consistent features to your model at inference time — without sacrificing reliability or throughput.
🧠 Best Practices for Reliable Operations
Operational reliability turns good architecture into production success. Consider these implementation rules:
🧩 Define versioned schemas and enforce governance at the feature level.
📊 Track feature lineage to quickly assess drift or data bias.
🔄 Automate sync checks between training and serving layers.
💰 Tune freshness versus cost through dynamic pipeline scheduling.
📡 Monitor latency and quality metrics just like uptime SLOs.
The best ML platform teams treat their feature stores as mission‑critical infrastructure, not just supporting utilities.
📈 Conclusion
In 2025, a well‑architected feature store determines the success of enterprise AI systems. Whether you build or buy, or mix batch with streaming, the north star remains clear: online/offline consistency and low‑latency inference must anchor every design choice.
As AI systems scale, the smartest teams will adopt a shared culture of observability, hybrid compute, and data product ownership — ensuring every feature served is fast, reliable, and fully trusted.